Whether you prefer “schema first” or “resolver first”, GraphQL development should definitely be “types first”. One aspect of planning your data types is nullability, and this is important to get right. Nullability in GraphQL is different than how we handle null values in other environments, like REST or gRPC APIs. You see, we expect a RESTful endpoint to either return an object, a list, or other piece(s) of data as a whole – or not at all. If a REST GET operation fails, we expect the entire request to have failed – not just a subset of the operation.
GraphQL is inherently different
However, that’s not how GraphQL rolls. It’s entirely acceptable and likely that most of your data graph will load successfully, except a small part will fail due to the composition of the many micro-services responsible for populating all of that data. When all of the fields in a type are marked as “non-nullable” (using the ! ), then that no longer allows a failure to occur gracefully.
Said differently, if any one non-nullable field defined in your type is ever null, or its resolver throws an exception, the entire query fails. Not cool.
Consider this example …
We’ve started a new schema for our app, and have defined a VacationRental and its associated types. Notice how everything is non-nullable by default, a common yet problematic approach when creating a new schema:
type Query {
vacationRentalById(id: $id) : VacationRental
}
type VacationRental {
id: ID!
title: String!
description: String!
owner: Owner!
roomCount: Int!
address: Address!
geolocation: GeoLocation!
price: Price!
}
type Owner {
name: String!
email: String!
phone: String!
twitterHandle: String!
inboxNotifications: [Notification]!
}
type Address {
line1: String!
line2: String!
city: String!
state: String!
zip: String!
}
type Price {
amount: Float!
currency: String!
}
type GeoLocation {
latitude: String!
longitude: String!
}
type Notification {
timestamp: String!
message: String!
}Let’s look at some of the problems this can lead to, and how we might better approach this initial schema creation …
Nullability is important to users
Kinda. They don’t care what it is, but it definitely affects their user experience. Using nullable fields in your GraphQL projections means that when (not if) one or more parts of a screen fail, the rest of the screen may remain perfectly usable (yay!). But it’s a real problem if a less-critical portion of your data becomes unavailable due to a database outage, or a hiccup in your network, or a good ol’ act of god, and suddenly your user cannot be successful in achieving whatever one thing was most important to them on that screen.
Allow your screen to fail gracefully
Think about our Vacation Rental example …
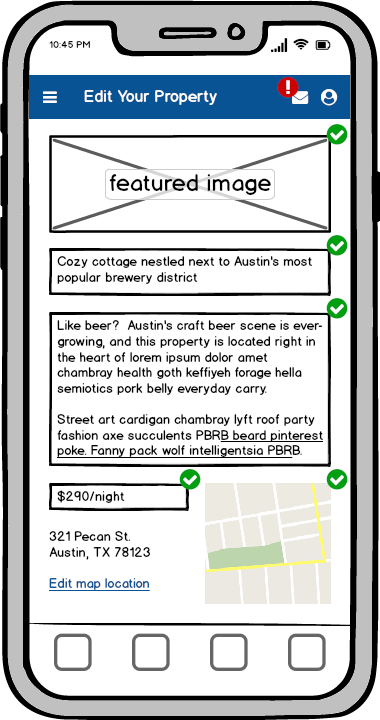
If the Owner of a vacation rental property is viewing their Property Editor screen, attempting to write an impactful headline and illustrative description for their new property, it’s not important that something small like an Inbox Notification shown in the Top Nav Bar fails. If the Notifications service is down for 20 mins, and the inboxNotifications field returns null, the rest of the query still succeeds and the Owner can accomplish their primary goal on that screen — playfully word-smithing the content that guests will see when viewing their property.
Let’s update our example to allow inboxNotifications to have a null value, meaning if the Notifications service fails, the property owner can still edit their listing:
# ...
type Owner {
name: String!
email: String!
phone: String!
twitterHandle: String!
inboxNotifications: [Notification] # removed the !
}
# ...
type Notification {
timestamp: String!
message: String!
}If your entire query fails, your UI can’t allow your user to have at least some success, or to be shown a specific and helpful message. When the entire query fails, all you can do is tell your user “Something broke, please try again” (even though you and I both know it won’t work when they try again.)
Users care that your app is resilient, and nullable fields on your GraphQL types allow portions of your screen to fail gracefully while the rest of the screen remains usable.
Think of nullable fields as error boundaries, which will likely align with the API service boundaries behind your GraphQL server 🤔
Offer a frictionless user flow
If we want to allow a property owner to incrementally save their progress while listing their gorgeous home for rent, we can’t require every field to be populated at once. If a user first enters their listing’s title, then description, then address — and each time the screen auto-saves their progress for a frictionless experience and a saved backup in case their computer and/or network starts acting up — then you must allow those fields to be nullable.
Let’s update our VacationRental type to be more flexible and enable that user experience …
# ...
type VacationRental {
id: ID!
title: String # removed the !
description: String # removed the !
owner: Owner!
roomCount: Int # removed the !
address: Address # removed the !
geolocation: GeoLocation # removed the !
price: Price # removed the !
}
# ...Now our typedef allows each field within our UI to be saved automatically as a user progresses through their workflow. Neato!
Describe your domain
Nullable fields in GraphQL should be used to accurately describe the business domain rules. For example, a company may require all Owners to enter their name, email, and phone so that Guests can get a hold of them.
But perhaps you don’t require every Owner to have a twitterHandle , because not everybody twitters. Let’s make that change, too:
# ...
type Owner {
name: String!
email: String!
phone: String!
twitterHandle: String # removed the !
inboxNotifications: [Notification]
}
# ...Facebook’s best practices
In the GraphQL docs, the Best Practices page advises to begin defining types using nullable fields, and only later might you decide to indicate specific fields as non-nullable when that guarantee can actually be made. But by default, allowing fields to be nullable improves the resiliency of the larger data graph:
“… in a GraphQL type system, every field is nullable by default. This is because there are many things which can go awry in a networked service backed by databases and other services. A database could go down, an asynchronous action could fail, an exception could be thrown.”
Yes, this might result in more null checks throughout your system, but you should probably be doing some of those anyway 🙂
If you’re working with JavaScript, things will get easier soon. Optional Chaining is at Stage-2 in TC39, and there’s a Babel plugin if you just can’t wait (some languages already have this feature, like Swift). And it’s much more painful trying to ensure that never once will any of your field data return null. (Good luck with that, though!)
But non-nullable is good, too!
Yup, it sure is! Let’s talk about when it’s a good idea to begin your schema design with non-nullable fields, because I’m definitely not preaching we should “nullable all the things!”
Some types don’t make sense without required fields
Let’s look at the GeoLocation and Notification types in the example …
A GeoLocation makes no sense at all with just a latitude , or just a longitude. And a Notification within your system will always contain a timestamp and a message , because it’s enforced in your nice type-safe backend. The amount of a Price isn’t enough to generate a transaction if you don’t know what currency is to be used.
There’s no reason to ever allow nulls in those fields, so we’ll leave those marked as non-nullable. This reduces your cyclomatic complexity, which is important to the amount of null checks (read: lines of code) you must write in your front-end to avoid errors, as well as the number of unit tests you must write to achieve good test coverage.
This increased verbosity, complexity and required tests is a great reason to always ask yourself, “Is it worth it to allow this field to actually be null?” 🤷♂️
Go faster, and go backwards
When you’re spinning up a new data graph, your project is probably evolving quickly with a team of people. Leaving GraphQL fields nullable frees you up to iterate faster, be flexible, and allow you to defer decisions about your data until the last responsible moment.
Some of those decisions are harder to ⌘-Z than others. Beginning your data graph with nullable type fields, then later on converting some fields to non-nullable is backwards-compatible. However, when you mark those fields as non-nullable from the start, it’s a lot more difficult to make them nullable later on, as there may be code in the wild that calls that data without null checks and your apps could crash.
This might be the opposite of how your input parameters work, but you’re probably still safer to start off with nullable parameters and enforce those required fields in your code if necessary.
The final schema
So after much pondering, we’ve made some important decisions about our schema. Here’s what I had as the first version in my head, is it what you would’ve done?
type Query {
vacationRentalById(id: $id) : VacationRental
}
type VacationRental {
id: ID!
title: String
description: String
owner: Owner!
roomCount: Int
address: Address
geolocation: GeoLocation
price: Price
}
type Owner {
name: String!
email: String!
phone: String!
twitterHandle: String
inboxNotifications: [Notification]
}
type Address {
line1: String!
line2: String
city: String!
state: String!
zip: String!
}
type Price {
amount: Float!
currency: String!
}
type GeoLocation {
latitude: String!
longitude: String!
}
type Notification {
timestamp: String!
message: String!
}